现在这个社会是信息爆炸的社会,各个网站、app上铺天盖地的都是各种新闻和信息。 为了获取信息,我们每天都要进行各种麻烦的操作,打开各种网站或者手机app,操作显得低效,后来发现了一个神器,那就是RSS。
RSS中文名是简易信息聚合,就是让网站一个按照一定周期更新网站的文章概要内容(有些是全文)到一个xml中。RSS订阅工具一定时间抓取这个RSS订阅源生成数据供订阅者读取网站内容。
有了RSS,你只要去订阅工具上就可以浏览你自己订阅的新的更新内容,非常简单高效。这里推荐一个RSS订阅神器inoreader,支持中文。这个我认为是目前最好的RSS订阅器。 知乎专栏是一个知乎开给个人写的博客,有些专栏具有有价值的信息,但是很遗憾知乎专栏不提供RSS订阅,当然作为开发者来说,我们可以自己动手做一个知乎专栏RSS抓取程序。
很多网站提供了RSS,但是更多网站其实没有提供RSS订阅源。我们可以使用爬虫抓取网站更新内容制作个人的RSS订阅源。我作为一个前端er可以使用nodejs来进行RSS的制作。
Node.js是一个基于Chrome Java运行时建立的平台, 用于方便地搭建响应速度快、易于扩展的网络应用。Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。
简单的说 Node.js 就是运行在服务端的 Java。使用nodejs的可以让你一个只会用Java也能写后端服务代码。当然也能用它进行爬虫抓取的工作。
进行爬取工作的话先要安装所要用到的依赖。superagent是最常用的一个依赖库,利用它可以轻松发送各种请求。cheerio就是一个nodejs版本的jquery,利用它可以获取网页中的各种dom结构。data2xml就是一个json成xml的一个库。 其他还有node-schedule和fs就是进行定时操作和文件操作。
我这次举例爬取一个专栏前端学习指南。想这种适配手机端的网页,一般都有采用发送API请求来获得数据进行前端渲染页面,我们可以用chrome的network的查看可疑的请求。打开chrome的开发者工具。我们很快就发现了一个目标。一个可疑请求


我们得到了一个json,我们现在使用一个json的查看工具chrome的插件JSON Editor可视化这个json数据方便我们进行分析。

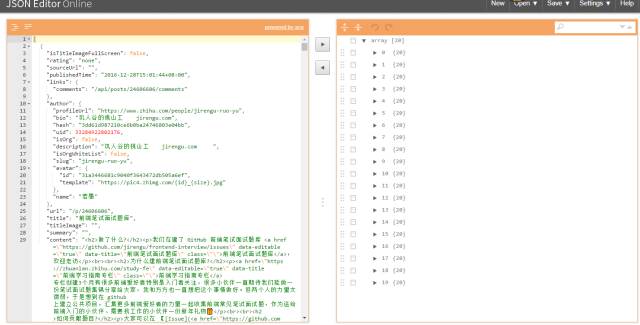
前面我们发现的请求发送里面有一个参数是limit,他的值是20,从上图我们知道了我们得到了20组数据,这个参数其实就是获取的数据条目数。我们现在分析20组里面的一条数据。
我们可以通过《XML那些事...》 实现简单的RSS可知RSS几个关键的值。跟上图截图的对应。
在一个RSS文档的开头是一个rss节和一个属性version,该属性了该文档将已RSS的哪个版本表示。如果该文档以这个规范来表示,那么它的version属性就必须等于2.0。在一个rss节点的下一级是一个的channel节点,该节点包含关于channel的信息和内容。(这个是必要的节点)内容信息使用item节点表示,item的子节点有title、link、author、pubDate、deion。以下标签是我们必须遵守的:rss:每个RSS Feed,都有而且只能有一个rss标签,作为顶层元素channel:在RSS标签下,必须有且只能有一个channel标签 item:可以出现多个item,每个item,描述一条日志信息 title:日志的标题 link:日志的URL访问地址 author:日志的作者 pubDate:日志的发布日期 deion:日志的内容
新建一个文件studyfe.js,在文件中用require引入各种依赖。然后我们用superagent获取数据后进行数组的拼装。
而在得到这个数组的时候,我们已经相当于得到了所有要采集的数据了,那下面要做的东西就很简单了,那就是json数组成xml格式。而我们我们要用到data2xml这个库。在开头我们已经require进来了。 data2xml的使用文档可以查看
输出到文件之后,然后要把这个文件放到服务器上,这样才能被rss服务器抓取到,如何放在服务器上这本文就不讨论了,还有一个问题就是RSS需要实时更新的,所以还有使用定时抓取,这次用到的是node-schedule。里面的定时写法其实跟linux中的crontab定时任务写法是很相似的。下面的代码其实代表着每3分钟定时执行一次。
定时执行任务还会有一个问题就是在nodejs在执行异常的时候退出,这样就会导致不会实时抓取,这个要用到一个nodejs中能自动重启任务的,我用的是pm2。 pm2的使用教程可以看这里,本文不详细展开。
最后,我是在linux下写出此教程的,实际跑的程现在放在vps上,在windows下不知道会出现什么问题,自己实践吧。全部代码已经上传到github。
推荐: